目录
一,简介
facebook提供API供开发者使用,目前版本可以用API在公共主页发布帖子,参考文档,api发布帖子比较简单,这里就不写了。
以前也可以用api在小组发布帖子,但是考虑垃圾信息处理问题,官方已经禁止api这个功能了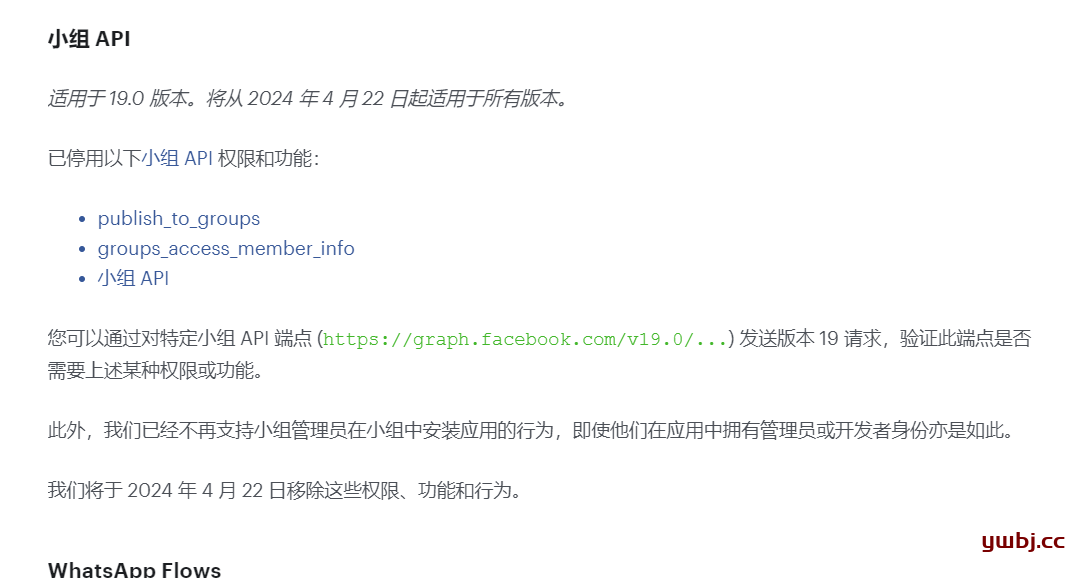
所有只能用其他方法发布帖子了,selenium 最早用于自动化测试,后面也可以用于爬虫,简单的理解就是自动帮你打开浏览器,输入密码,模拟人为操作等一系列动作。这时就可以用selenium 自动完成发布小组帖子了。
自动运行效果参考,facebook电影小组 小组所有信息由脚本发送。
二,代码功能方法介绍
通过 Selenium 模拟浏览器自动化操作,结合 MySQL 数据库获取内容,来实现定时向 Facebook 群组发布最新电影更新的功能。它还涉及到登录 Facebook、保存 Cookies、下载图片以及发布评论。下面是脚本的整个运行流程。
1. 初始化和配置
logging:配置日志输出格式和等级。
load_dotenv():加载环境变量文件 .env 中的变量,以便使用其中的数据库和 Facebook 登录凭据。
Chrome 浏览器选项:使用 Chrome 浏览器的“无头模式”,并设置中文界面。无头模式下浏览器在后台运行,提高了效率。
2. Facebook 登录和 Cookies 管理
facebook_login():检查是否已登录 Facebook。如果有 Cookies 文件,则加载 Cookies 并刷新页面以验证登录状态;否则进入登录页面,输入账号密码,并点击登录按钮完成登录。成功登录后,保存 Cookies,以便下次免登录。
is_logged_in():通过检查 Facebook 首页是否加载来确认是否登录成功。
save_cookies(driver, path) 和 load_cookies(driver, path):分别用于保存和加载浏览器的 Cookies 文件,使用户下次登录时可以复用登录状态,避免频繁登录。
3. 数据库连接和电影数据获取
fetch_movie_updates():连接到 MySQL 数据库,查询最近 2 小时内的电影更新信息(包括电影 ID、名称、类别、年份、封面图等),然后将查询结果返回。
4. 图片下载
download_image(image_url, save_path):接收图片的 URL,下载后保存到指定的文件路径,并返回图片保存路径。用于在发布 Facebook 帖子时附上电影封面图片。
5. 发布帖子和添加评论
post_to_group(message, image_path=None, movie_id=None):在指定的 Facebook 群组中发布帖子,过程包括:
打开群组页面,等待加载。
点击“添加照片/视频”按钮,上传图片文件(如果有)。
输入帖子内容并点击发布。
发布成功后调用 post_comments() 函数,添加评论。
post_comments(movie_id):找到刚刚发布的帖子,在其下方依次发布两条评论,其中包含播放链接和推广信息。
6. 主函数 main()
main():这是整个程序的主入口。流程包括:
调用 fetch_movie_updates() 获取数据库中的最新电影数据。
如果没有新的电影数据,则退出程序。
否则,调用 facebook_login() 登录 Facebook。
依次处理每部电影,将内容构建为帖子,并调用 post_to_group() 发布至 Facebook 群组,最后调用 post_comments() 为每个帖子添加评论。
7.其他注意事项:
表情其他特殊符号问题
chromeDriver 谷歌不能发送表情包,否则报错”selenium.common.exceptions.WebDriverException: Message: unknown error: ChromeDriver only supports characters in the BMP“
解决方法:1:网上有JS注入方法,没测试过。
2:使用Firefox 浏览器,测试可用使用emoji表情包。
三,代码
测试可以在windows电脑上测试,注释掉无头模式,就是以下代码。
chrome_options.add_argument("--headless") # 启用无头模式
还有以下代码是Linux运行的代码,有些路径需要改成windows格式,如:
image_filename = f"images/{movie['vod_id']}.jpg" #Linux格式
image_filename = rf"images\{movie['vod_id']}.jpg" #windows格式
部分代码如下,完整代码见文章最后:
from dotenv import load_dotenv
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
import mysql.connector
import time
import os
import logging
import requests
import json
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# 加载环境变量
load_dotenv()
FB_EMAIL = os.getenv('FB_EMAIL')
#FB_EMAIL = '[email protected]'
FB_PASSWORD = os.getenv('FB_PASSWORD')
#FB_PASSWORD = 'baichi_9408'
GROUP_URL = os.getenv('GROUP_URL')
DB_USER = os.getenv('DB_USER')
DB_PASSWORD = os.getenv('DB_PASSWORD')
DB_HOST = os.getenv('DB_HOST')
DB_NAME = os.getenv('DB_NAME')
# 配置 Chrome 选项(无头模式)
chrome_options = Options()
chrome_options.add_argument("--headless") # 启用无头模式
chrome_options.add_argument("--disable-gpu") # 禁用 GPU 加速
chrome_options.add_argument("--no-sandbox") # 绕过 OS 安全模型
chrome_options.add_argument("--disable-dev-shm-usage") # 克服有限资源问题
chrome_options.add_argument("--disable-notifications") # 禁用通知
chrome_options.add_argument("--start-maximized") # 最大化窗口
chrome_options.add_argument("--window-size=1920,1080") # 设置窗口大小
chrome_options.add_argument("--disable-extensions") # 禁用扩展
chrome_options.add_argument("--disable-infobars") # 禁用信息栏
# 设置语言为中文
chrome_options.add_argument("--lang=zh-CN") # 简体中文
# 或者使用繁体中文
# chrome_options.add_argument("--lang=zh-TW")
# 可选:设置接受的语言首选项
prefs = {"intl.accept_languages": "zh-CN"}
chrome_options.add_experimental_option("prefs", prefs)
# 初始化 WebDriver
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=chrome_options)
def save_cookies(driver, path):
"""
将浏览器的 Cookies 保存到指定路径的 JSON 文件中。
"""
with open(path, 'w') as file:
json.dump(driver.get_cookies(), file)
logging.info(f"Cookies 已保存到 {path}")
def load_cookies(driver, path):
"""
从指定路径的 JSON 文件中加载 Cookies 并添加到浏览器中。
"""
try:
with open(path, 'r') as file:
cookies = json.load(file)
for cookie in cookies:
# 删除 'expiry' 属性,因为有时它可能导致问题
if 'expiry' in cookie:
del cookie['expiry']
driver.add_cookie(cookie)
logging.info(f"Cookies 已从 {path} 加载")
except FileNotFoundError:
logging.warning(f"Cookies 文件 {path} 未找到,需进行登录")
except Exception as e:
logging.error(f"加载 Cookies 时发生错误: {e}")
def is_logged_in(driver):
"""
检查当前会话是否已登录 Facebook。
"""
try:
# 等待元素出现,以确保页面已完全加载
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.XPATH, "//a[@aria-label='首页']"))
)
return True
except:
return False
def save_cookies(driver, path):
"""
将浏览器的 Cookies 保存到指定路径的 JSON 文件中。
"""
with open(path, 'w') as file:
json.dump(driver.get_cookies(), file)
logging.info(f"Cookies 已保存到 {path}")
def load_cookies(driver, path):
"""
从指定路径的 JSON 文件中加载 Cookies 并添加到浏览器中。
"""
try:
with open(path, 'r') as file:
cookies = json.load(file)
for cookie in cookies:
# 删除 'expiry' 属性,因为有时它可能导致问题
if 'expiry' in cookie:
del cookie['expiry']
driver.add_cookie(cookie)
logging.info(f"Cookies 已从 {path} 加载")
except FileNotFoundError:
logging.warning(f"Cookies 文件 {path} 未找到,需进行登录")
except Exception as e:
logging.error(f"加载 Cookies 时发生错误: {e}")
def facebook_login(driver, cookies_path='cookies.json'):
"""
使用 Selenium 自动登录 Facebook,并保存登录后的 Cookies。
"""
#内容省略...
def fetch_movie_updates():
"""
连接 MySQL 数据库并获取最近2小时内的电影更新信息。
"""
try:
connection = mysql.connector.connect(
user=DB_USER,
password=DB_PASSWORD,
host=DB_HOST,
database=DB_NAME
)
cursor = connection.cursor(dictionary=True)
# 查询数据库获取最近2小时内的电影更新信息
query = """
SELECT vod_id, vod_name, vod_class, vod_year, vod_pic, vod_area, vod_blurb
FROM mac_vod
WHERE FROM_UNIXTIME(vod_time) >= NOW() - INTERVAL 2 HOUR
AND type_id_1 = 1
ORDER BY vod_time DESC
"""
cursor.execute(query)
result = cursor.fetchall()
cursor.close()
connection.close()
logging.info(f"获取到 {len(result)} 条电影更新。")
return result
except mysql.connector.Error as err:
logging.error(f"数据库错误: {err}")
return []
def download_image(image_url, save_path):
"""
下载图片并保存到本地。
"""
try:
response = requests.get(image_url, stream=True)
if response.status_code == 200:
with open(save_path, 'wb') as f:
for chunk in response.iter_content(1024):
f.write(chunk)
logging.info(f"图片已下载到 {save_path}")
return save_path
else:
logging.error(f"无法下载图片: {image_url}")
return None
except Exception as e:
logging.error(f"下载图片时发生错误: {e}")
return None
def post_comments(movie_id):
"""
在刚发布的帖子下添加两条评论。
"""
#内容省略...
def post_to_group(message, image_path=None, movie_id=None):
#内容省略...
def main():
# 获取最新的电影更新
movies = fetch_movie_updates()
if not movies:
logging.info("过去2小时内没有新的电影更新。")
driver.quit()
return
# 登录 Facebook
facebook_login(driver)
for movie in movies:
# 构建帖子内容
message = (
"有味影視資ywtv源更新:\n"
"-------------------------------------------\n"
"↓↓線上播放地址請見評論區↓↓\n"
"-------------------------------------------\n"
f"-片名:【{movie['vod_name']}】\n"
"-------------------------------------------\n"
f"-類型:【{movie['vod_class']}/{movie['vod_area']}/{movie['vod_year']}】\n"
"-------------------------------------------\n"
f"-簡介:{movie['vod_blurb']}\n"
)
# 如果有图片链接,下载图片
image_path = None
if movie.get('vod_pic'):
IMG_BASE_URL = 'https://ywtv.live/' # 图片的基础 URL
image_url = f"{IMG_BASE_URL}{movie['vod_pic']}"
image_filename = f"images/{movie['vod_id']}.jpg" # 保存路径
os.makedirs(os.path.dirname(image_filename), exist_ok=True)
downloaded_image = download_image(image_url, image_filename)
if downloaded_image:
image_path = image_filename
# 发布帖子并添加评论
post_to_group(message, image_path, movie_id=movie['vod_id'])
time.sleep(120) # 每条消息间隔120秒,防止触发 Facebook 反自动化机制
driver.quit()
if __name__ == "__main__":
main()
四,Linux服务器运行
Linux server版没有界面,而且安装依赖包比较多,可以使用python的虚拟环境,单独的环境运行,不影响主机的环境。
1,使用虚拟环境可以隔离项目的依赖关系。
sudo apt install python3-venv -y
python3 -m venv myenv
source myenv/bin/activate
激活后,您的终端提示符会显示 (myenv),表示虚拟环境已激活。
2,在虚拟环境安装必要的python库
使用 pip 安装脚本中使用的所有库。可以创建一个 requirements.txt 文件以简化安装过程。
vim requirements.txt
#将以下内容粘贴到文件中
python-dotenv
selenium
webdriver-manager
mysql-connector-python
emoji
requests
退出运行安装
pip3 install -r requirements.txt
3,安装 Google Chrome
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
sudo apt install ./google-chrome-stable_current_amd64.deb -y
安装完成,可以用以下命令验证安装
google-chrome --version
4,环境变量
脚本使用 .env 文件来加载环境变量。按照以下步骤创建并配置 .env 文件。
vim .env
#配置以下内容
FB_EMAIL=your_facebook_email
FB_PASSWORD=your_facebook_password
GROUP_URL=https://www.facebook.com/groups/your_group_id
DB_USER=your_db_username
DB_PASSWORD=your_db_password
DB_HOST=your_db_host
DB_NAME=your_db_name
注意:确保 .env 文件的权限设置正确,以保护敏感信息。
chmod 600 .env
5,定时任务脚本
目前结构如下:
/home/ubuntu/facebook_bot/
│
├── venv/
│ └── ... (虚拟环境文件)
├── facebook_bot.py
├── requirements.txt
├── run_facebook_bot.sh
└── .env
Linux运行脚本run_facebook_bot.sh 如下:
#!/bin/bash
# 设置项目目录
PROJECT_DIR="/home/ubuntu/facebook_bot"
# 切换到项目目录
cd "$PROJECT_DIR" || exit
# 激活虚拟环境
source venv/bin/activate
# 运行 Python 脚本,并将输出重定向到日志文件
python3 facebook_bot.py >> logs/facebook_bot.log 2>&1
# 退出虚拟环境
deactivate
最后定时任务:
crontab -e
#每2小时运行一次
0 */2 * * * bash /home/ubuntu/facebook_bot/run_facebook_bot.sh