目录
一,es api查询命令测试
这里是基于opensearch + fluent-bit 系统搭建。搭建参考:OpenSearch + Fluent Bit日志管理系统
当然elasticsearch API基本都是通用的,可根据自己配置的索引,和匹配的值查询。
如这里匹配dev-gateway-logs* 的索引,根据 level日志级别为ERROR查询24h之内的日志,如果日志没有提取level字段,根据其他字段查询。
关于字段提取参考:Opensearch 日志告警配置
curl -s -k -u 'dev:qwe123' -X POST "https://192.168.10.10:9200/dev-gateway-logs*/_search?pretty" -H 'Content-Type: application/json' -d '{
"size": 10,
"query": {
"bool": {
"must": [
{ "match": { "level": "ERROR" } },
{ "range": { "@timestamp": { "gte": "now-24h", "lte": "now" } } }
]
}
},
"sort": [
{ "@timestamp": { "order": "desc" } }
]
}'
-k :open search 默认开启https访问,所以需要-k 跳过ssl验证。
curl访问得到日志参考如下,可以正常获取日志即可。
...
{
"_index" : "dev-gateway-logs-000032",
"_id" : "o2PpG5gBCkl4q0xX9Uql",
"_score" : null,
"_source" : {
"@timestamp" : "2025-07-18T05:02:51.944Z",
"level" : "ERROR",
"log" : "2025-07-18 13:02:51.943 [reactor-http-epoll-1] ERROR gateway.handler.GatewayExceptionHandler GatewayExceptionHandler.java:handle:48 - [] [Gateway]请求路径:/admin/list, 异常信息:cn.dev33.satoken.exception.NotLoginException: token 无效:eyJ0eXAiOiJKV1QiLCJhbGciOiJIUzI1NiJ9.eyJsb2dpblR5cGUiOiJsb2dpbiIsImxvZ2luSWQiOjE5LCJyblN0ciI6InppbVZrbEdQUktHZ2JsbVNrcnZaazlDQUl2eXU5VGR5In0.qWIMIRf93_d28IwBUmgt6_G2zvXFypliEE-b_U8BwcM, 诊断:账号未登录,或token已失效 \n"
},
"sort" : [
1752814971944
]
}
...
二,python脚本发送至telegram bot
1,python环境准备
这里使用python的虚拟环境,单独的环境运行,不影响主机的环境。
#安装虚拟环境
sudo apt install python3-venv -y
#创建虚拟环境配置
python3 -m venv myenv
#进入虚拟环境配置
source myenv/bin/activate
创建requirements.txt ,将安装的依赖写入
python-telegram-bot==20.7
aiohttp==3.9.1
asyncio
执行安装依赖
pip3 install -r requirements.txt
2,python脚本
需求,根据选择的索引,和时间,获取ERROR日志。
分页显示,每页显示5条(可调整)。
创建脚本文件elasticsearch_bot.py
import asyncio
import json
import logging
from datetime import datetime, timedelta, timezone
from typing import Dict, List, Optional
import aiohttp
import base64
from telegram import Update, InlineKeyboardButton, InlineKeyboardMarkup
from telegram.ext import Application, CommandHandler, CallbackQueryHandler, ContextTypes
from telegram.constants import ParseMode
# 配置日志
logging.basicConfig(
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
level=logging.INFO
)
logger = logging.getLogger(__name__)
# 配置信息
TELEGRAM_BOT_TOKEN = "1233456:AAFYy_X0YN3dH42C1d2WXasdasd123"
ELASTICSEARCH_URL = "https://192.168.10.10:9200"
ELASTICSEARCH_USER = "dev"
ELASTICSEARCH_PASSWORD = "qwe123"
# 索引选项
INDEX_OPTIONS = {
"gateway": "dev-gateway-logs*",
"user-service": "dev-user-service-logs*",
"payment-service": "dev-payment-service-logs*",
"notification-service": "dev-notification-service-logs*"
}
# 时间选项
TIME_OPTIONS = {
"1小时": "now-1h",
"6小时": "now-6h",
"12小时": "now-12h",
"24小时": "now-24h",
"3天": "now-3d",
"7天": "now-7d"
}
class ElasticsearchBot:
def __init__(self):
self.session = None
self.auth_header = self._create_auth_header()
def _create_auth_header(self) -> str:
"""创建基本认证头"""
auth_string = f"{ELASTICSEARCH_USER}:{ELASTICSEARCH_PASSWORD}"
encoded_auth = base64.b64encode(auth_string.encode()).decode()
return f"Basic {encoded_auth}"
async def _get_session(self) -> aiohttp.ClientSession:
"""获取或创建 aiohttp session"""
if self.session is None or self.session.closed:
connector = aiohttp.TCPConnector(ssl=False) # 对应 curl 的 -k 参数
self.session = aiohttp.ClientSession(connector=connector)
return self.session
async def search_logs(self, index: str, time_range: str, page: int = 0, size: int = 10) -> Dict:
"""搜索 Elasticsearch 日志"""
query = {
"size": size,
"from": page * size,
"query": {
"bool": {
"must": [
{"match": {"level": "ERROR"}},
{"range": {"@timestamp": {"gte": time_range, "lte": "now"}}}
]
}
},
"sort": [
{"@timestamp": {"order": "desc"}}
]
}
headers = {
"Content-Type": "application/json",
"Authorization": self.auth_header
}
try:
session = await self._get_session()
async with session.post(
f"{ELASTICSEARCH_URL}/{index}/_search",
headers=headers,
json=query
) as response:
if response.status == 200:
return await response.json()
else:
logger.error(f"Elasticsearch 请求失败: {response.status}")
return {"error": f"请求失败: {response.status}"}
except Exception as e:
logger.error(f"搜索日志时发生错误: {e}")
return {"error": str(e)}
async def close(self):
"""关闭 session"""
if self.session and not self.session.closed:
await self.session.close()
# 全局 Elasticsearch 客户端
es_client = ElasticsearchBot()
async def start(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""开始命令处理"""
keyboard = [
[InlineKeyboardButton("📊 查询错误日志", callback_data="query_logs")]
]
reply_markup = InlineKeyboardMarkup(keyboard)
await update.message.reply_text(
"👋 欢迎使用 Elasticsearch 日志查询机器人!\n\n"
"点击下方按钮开始查询错误日志。",
reply_markup=reply_markup
)
async def query_logs(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""开始查询流程 - 选择索引"""
query = update.callback_query
await query.answer()
keyboard = []
for display_name, index_name in INDEX_OPTIONS.items():
keyboard.append([InlineKeyboardButton(display_name, callback_data=f"index_{index_name}")])
reply_markup = InlineKeyboardMarkup(keyboard)
await query.edit_message_text(
"🔍 请选择要查询的索引:",
reply_markup=reply_markup
)
async def select_index(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""选择索引后选择时间范围"""
query = update.callback_query
await query.answer()
index = query.data.replace("index_", "")
context.user_data['selected_index'] = index
keyboard = []
for display_name, time_range in TIME_OPTIONS.items():
keyboard.append([InlineKeyboardButton(display_name, callback_data=f"time_{time_range}")])
reply_markup = InlineKeyboardMarkup(keyboard)
await query.edit_message_text(
f"📅 已选择索引: `{index}`\n\n请选择时间范围:",
reply_markup=reply_markup,
parse_mode=ParseMode.MARKDOWN
)
async def select_time_and_search(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""选择时间范围后执行搜索"""
query = update.callback_query
await query.answer()
time_range = query.data.replace("time_", "")
index = context.user_data.get('selected_index')
if not index:
await query.edit_message_text("❌ 错误:未选择索引,请重新开始。")
return
# 保存搜索参数
context.user_data['search_params'] = {
'index': index,
'time_range': time_range,
'current_page': 0
}
await query.edit_message_text("🔍 正在搜索日志...")
# 执行搜索
await perform_search(update, context)
async def perform_search(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""执行搜索并显示结果"""
search_params = context.user_data.get('search_params')
if not search_params:
return
query = update.callback_query
page = search_params['current_page']
# 搜索日志
result = await es_client.search_logs(
index=search_params['index'],
time_range=search_params['time_range'],
page=page,
size=5 # 每页显示5条记录
)
if "error" in result:
await query.edit_message_text(f"❌ 搜索失败: {result['error']}")
return
hits = result.get('hits', {})
total_hits = hits.get('total', {}).get('value', 0)
logs = hits.get('hits', [])
if total_hits == 0:
await query.edit_message_text("📝 未找到符合条件的错误日志。")
return
# 构建消息
message = f"📊 **日志查询结果** (第 {page + 1} 页)\n\n"
message += f"**索引**: `{search_params['index']}`\n"
message += f"**时间范围**: {search_params['time_range']}\n"
message += f"**总记录数**: {total_hits}\n\n"
for i, log in enumerate(logs, 1):
source = log.get('_source', {})
timestamp = source.get('@timestamp', 'N/A')
log_message = source.get('log', source.get('message', 'N/A'))
# 格式化时间戳
if timestamp != 'N/A':
try:
dt = datetime.fromisoformat(timestamp.replace('Z', '+00:00'))
dt = dt.astimezone(timezone(timedelta(hours=8)))
formatted_time = dt.strftime('%Y-%m-%d %H:%M:%S')
except Exception as e:
print("时间转换失败,异常:", e)
formatted_time = timestamp
else:
formatted_time = 'N/A'
message += f"**{page * 5 + i}.** `{formatted_time}`\n"
# 限制日志消息长度
if len(log_message) > 500:
log_message = log_message[:500] + "..."
message += f"```\n{log_message}\n```\n"
# 构建分页按钮
keyboard = []
nav_buttons = []
if page > 0:
nav_buttons.append(InlineKeyboardButton("⬅️ 上一页", callback_data="prev_page"))
if (page + 1) * 5 < total_hits:
nav_buttons.append(InlineKeyboardButton("➡️ 下一页", callback_data="next_page"))
if nav_buttons:
keyboard.append(nav_buttons)
keyboard.append([InlineKeyboardButton("🔄 重新查询", callback_data="query_logs")])
reply_markup = InlineKeyboardMarkup(keyboard)
await query.edit_message_text(
message,
reply_markup=reply_markup,
parse_mode=ParseMode.MARKDOWN
)
async def handle_pagination(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""处理分页"""
query = update.callback_query
await query.answer()
search_params = context.user_data.get('search_params')
if not search_params:
await query.edit_message_text("❌ 错误:搜索参数丢失,请重新开始。")
return
if query.data == "prev_page":
search_params['current_page'] = max(0, search_params['current_page'] - 1)
elif query.data == "next_page":
search_params['current_page'] += 1
await perform_search(update, context)
async def error_handler(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""错误处理"""
logger.error(f"异常发生: {context.error}")
if update.effective_message:
await update.effective_message.reply_text(
"❌ 发生了一个错误,请稍后再试。"
)
async def shutdown(application):
"""关闭时清理资源"""
await es_client.close()
def main():
"""主函数"""
# 创建应用
application = Application.builder().token(TELEGRAM_BOT_TOKEN).build()
# 添加处理器
application.add_handler(CommandHandler("start", start))
application.add_handler(CallbackQueryHandler(query_logs, pattern="^query_logs$"))
application.add_handler(CallbackQueryHandler(select_index, pattern="^index_"))
application.add_handler(CallbackQueryHandler(select_time_and_search, pattern="^time_"))
application.add_handler(CallbackQueryHandler(handle_pagination, pattern="^(prev_page|next_page)$"))
# 添加错误处理器
application.add_error_handler(error_handler)
# 启动机器人
print("🤖 Elasticsearch 日志查询机器人启动中...")
application.run_polling(drop_pending_updates=True)
if __name__ == "__main__":
main()
3,运行测试
填写好自己服务器的elastic地址,账号密码,以及机器人token后,执行
python3 elasticsearch_bot.py
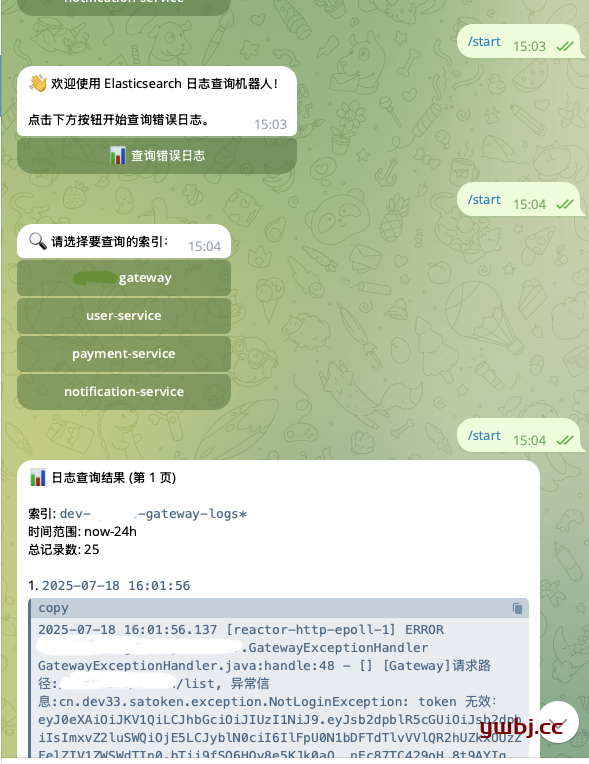
根据提示,选择服务或者索引,和时间后,会显示生成相关日志。
三,增加白名单和显示优化
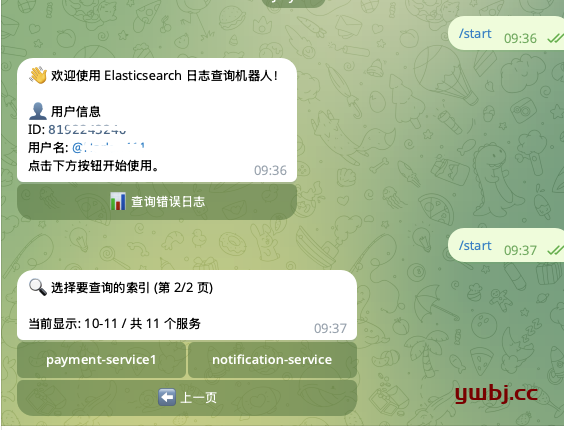
白名单:日志系统,一般只有内部相关人员可查看,防止bot被滥用,所以需要增加白名单功能。
通过 @userinfobot 可查看自己用户ID, id唯一的,不会改变,所以通过id配置白名单。
服务分页显示:增加分页功能,否则几十个服务,一页显示不友好。
import asyncio
import json
import logging
from datetime import datetime, timedelta, timezone
from typing import Dict, List, Optional, Set
import aiohttp
import base64
from functools import wraps
from telegram import Update, InlineKeyboardButton, InlineKeyboardMarkup
from telegram.ext import Application, CommandHandler, CallbackQueryHandler, ContextTypes, MessageHandler, filters
from telegram.constants import ParseMode
# 配置日志
logging.basicConfig(
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
level=logging.INFO
)
logger = logging.getLogger(__name__)
# 配置信息
TELEGRAM_BOT_TOKEN = "1233456:AAFYy_X0YN3dH42C1d2WXasdasd123"
ELASTICSEARCH_URL = "https://192.168.10.10:9200"
ELASTICSEARCH_USER = "dev"
ELASTICSEARCH_PASSWORD = "qwe123"
# 白名单配置 - 只有这些 Telegram ID 可以使用机器人
WHITELIST_USER_IDS = {
81922432461, # 用户1的 Telegram ID
987654321, # 用户2的 Telegram ID
555666777, # 用户3的 Telegram ID
# 在这里添加更多授权用户的 ID
}
# 索引选项
INDEX_OPTIONS = {
"gateway": "dev-gateway-logs*",
"user-service3": "dev-user-service3-logs*",
"user-service4": "dev-user-service4-logs*",
"user-service5": "dev-user-service5-logs*",
"user-service6": "dev-user-service6-logs*",
"payment-service": "dev-payment-service-logs*",
"payment-service1": "dev-payment-service1-logs*",
"notification-service": "dev-notification-service-logs*"
}
# 时间选项
TIME_OPTIONS = {
"1小时": "now-1h",
"6小时": "now-6h",
"12小时": "now-12h",
"24小时": "now-24h",
"3天": "now-3d",
"7天": "now-7d"
}
class ElasticsearchBot:
def __init__(self):
self.session = None
self.auth_header = self._create_auth_header()
def _create_auth_header(self) -> str:
"""创建基本认证头"""
auth_string = f"{ELASTICSEARCH_USER}:{ELASTICSEARCH_PASSWORD}"
encoded_auth = base64.b64encode(auth_string.encode()).decode()
return f"Basic {encoded_auth}"
async def _get_session(self) -> aiohttp.ClientSession:
"""获取或创建 aiohttp session"""
if self.session is None or self.session.closed:
connector = aiohttp.TCPConnector(ssl=False) # 对应 curl 的 -k 参数
self.session = aiohttp.ClientSession(connector=connector)
return self.session
async def search_logs(self, index: str, time_range: str, page: int = 0, size: int = 10) -> Dict:
"""搜索 Elasticsearch 日志"""
query = {
"size": size,
"from": page * size,
"query": {
"bool": {
"must": [
{"match": {"level": "ERROR"}},
{"range": {"@timestamp": {"gte": time_range, "lte": "now"}}}
]
}
},
"sort": [
{"@timestamp": {"order": "desc"}}
]
}
headers = {
"Content-Type": "application/json",
"Authorization": self.auth_header
}
try:
session = await self._get_session()
async with session.post(
f"{ELASTICSEARCH_URL}/{index}/_search",
headers=headers,
json=query
) as response:
if response.status == 200:
return await response.json()
else:
logger.error(f"Elasticsearch 请求失败: {response.status}")
return {"error": f"请求失败: {response.status}"}
except Exception as e:
logger.error(f"搜索日志时发生错误: {e}")
return {"error": str(e)}
async def close(self):
"""关闭 session"""
if self.session and not self.session.closed:
await self.session.close()
# 全局 Elasticsearch 客户端
es_client = ElasticsearchBot()
def whitelist_required(func):
"""白名单装饰器 - 检查用户是否在白名单中"""
@wraps(func)
async def wrapper(update: Update, context: ContextTypes.DEFAULT_TYPE):
user_id = update.effective_user.id
username = update.effective_user.username or "N/A"
if user_id not in WHITELIST_USER_IDS:
logger.warning(f"未授权用户尝试访问: ID={user_id}, Username={username}")
await update.effective_message.reply_text(
"❌ **访问被拒绝**\n\n"
"抱歉,您没有权限使用此机器人。\n"
f"您的 Telegram ID: `{user_id}`\n\n"
"如需访问权限,请联系管理员。",
parse_mode=ParseMode.MARKDOWN
)
return
logger.info(f"授权用户访问: ID={user_id}, Username={username}")
return await func(update, context)
return wrapper
@whitelist_required
async def start(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""开始命令处理"""
user_id = update.effective_user.id
username = update.effective_user.username or "N/A"
keyboard = [
[InlineKeyboardButton("📊 查询错误日志", callback_data="query_logs")]
]
reply_markup = InlineKeyboardMarkup(keyboard)
welcome_message = (
f"👋 欢迎使用 Elasticsearch 日志查询机器人!\n\n"
f"👤 **用户信息**\n"
f"ID: `{user_id}`\n"
f"用户名: @{username}\n"
f"点击下方按钮开始使用。"
)
await update.message.reply_text(
welcome_message,
reply_markup=reply_markup,
parse_mode=ParseMode.MARKDOWN
)
@whitelist_required
async def query_logs(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""开始查询流程 - 选择索引(支持分页)"""
query = update.callback_query
await query.answer()
# 重置索引页面参数
context.user_data['index_page'] = 0
await show_index_page(update, context)
@whitelist_required
async def show_index_page(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""显示索引选择页面"""
query = update.callback_query
current_page = context.user_data.get('index_page', 0)
# 每页显示的服务数量
items_per_page = 9
# 获取所有索引选项
all_indices = list(INDEX_OPTIONS.items())
total_pages = (len(all_indices) + items_per_page - 1) // items_per_page
# 计算当前页的索引范围
start_idx = current_page * items_per_page
end_idx = min(start_idx + items_per_page, len(all_indices))
current_indices = all_indices[start_idx:end_idx]
# 构建键盘
keyboard = []
# 添加当前页的索引按钮(每行2个)
for i in range(0, len(current_indices), 3):
row = []
for j in range(3):
if i + j < len(current_indices):
display_name, index_name = current_indices[i + j]
row.append(InlineKeyboardButton(display_name, callback_data=f"index_{index_name}"))
keyboard.append(row)
# 添加分页导航按钮
nav_buttons = []
if current_page > 0:
nav_buttons.append(InlineKeyboardButton("⬅️ 上一页", callback_data="index_prev_page"))
if current_page < total_pages - 1:
nav_buttons.append(InlineKeyboardButton("➡️ 下一页", callback_data="index_next_page"))
if nav_buttons:
keyboard.append(nav_buttons)
reply_markup = InlineKeyboardMarkup(keyboard)
# 构建消息文本
message = f"🔍 **选择要查询的索引** (第 {current_page + 1}/{total_pages} 页)\n\n"
message += f"当前显示: {start_idx + 1}-{end_idx} / 共 {len(all_indices)} 个服务"
if query:
await query.edit_message_text(
message,
reply_markup=reply_markup,
parse_mode=ParseMode.MARKDOWN
)
else:
await update.message.reply_text(
message,
reply_markup=reply_markup,
parse_mode=ParseMode.MARKDOWN
)
@whitelist_required
async def handle_index_pagination(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""处理索引分页"""
query = update.callback_query
await query.answer()
current_page = context.user_data.get('index_page', 0)
if query.data == "index_prev_page":
context.user_data['index_page'] = max(0, current_page - 1)
elif query.data == "index_next_page":
context.user_data['index_page'] = current_page + 1
await show_index_page(update, context)
@whitelist_required
async def select_index(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""选择索引后选择时间范围"""
query = update.callback_query
await query.answer()
index = query.data.replace("index_", "")
context.user_data['selected_index'] = index
keyboard = []
for display_name, time_range in TIME_OPTIONS.items():
keyboard.append([InlineKeyboardButton(display_name, callback_data=f"time_{time_range}")])
reply_markup = InlineKeyboardMarkup(keyboard)
await query.edit_message_text(
f"📅 已选择索引: `{index}`\n\n请选择时间范围:",
reply_markup=reply_markup,
parse_mode=ParseMode.MARKDOWN
)
@whitelist_required
async def select_time_and_search(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""选择时间范围后执行搜索"""
query = update.callback_query
await query.answer()
time_range = query.data.replace("time_", "")
index = context.user_data.get('selected_index')
if not index:
await query.edit_message_text("❌ 错误:未选择索引,请重新开始。")
return
# 保存搜索参数
context.user_data['search_params'] = {
'index': index,
'time_range': time_range,
'current_page': 0
}
await query.edit_message_text("🔍 正在搜索日志...")
# 执行搜索
await perform_search(update, context)
@whitelist_required
async def perform_search(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""执行搜索并显示结果"""
search_params = context.user_data.get('search_params')
if not search_params:
return
query = update.callback_query
page = search_params['current_page']
# 搜索日志
result = await es_client.search_logs(
index=search_params['index'],
time_range=search_params['time_range'],
page=page,
size=5 # 每页显示5条记录
)
if "error" in result:
await query.edit_message_text(f"❌ 搜索失败: {result['error']}")
return
hits = result.get('hits', {})
total_hits = hits.get('total', {}).get('value', 0)
logs = hits.get('hits', [])
if total_hits == 0:
await query.edit_message_text("📝 未找到符合条件的错误日志。")
return
# 构建消息
message = f"📊 **日志查询结果** (第 {page + 1} 页)\n\n"
message += f"**索引**: `{search_params['index']}`\n"
message += f"**时间范围**: {search_params['time_range']}\n"
message += f"**总记录数**: {total_hits}\n\n"
for i, log in enumerate(logs, 1):
source = log.get('_source', {})
timestamp = source.get('@timestamp', 'N/A')
log_message = source.get('log', source.get('message', 'N/A'))
# 格式化时间戳
if timestamp != 'N/A':
try:
dt = datetime.fromisoformat(timestamp.replace('Z', '+00:00'))
dt = dt.astimezone(timezone(timedelta(hours=8)))
formatted_time = dt.strftime('%Y-%m-%d %H:%M:%S')
except:
formatted_time = timestamp
else:
formatted_time = 'N/A'
message += f"**{page * 5 + i}.** `{formatted_time}`\n"
# 限制日志消息长度
if len(log_message) > 500:
log_message = log_message[:500] + "..."
message += f"```\n{log_message}\n```\n"
# 构建分页按钮
keyboard = []
nav_buttons = []
if page > 0:
nav_buttons.append(InlineKeyboardButton("⬅️ 上一页", callback_data="prev_page"))
if (page + 1) * 5 < total_hits:
nav_buttons.append(InlineKeyboardButton("➡️ 下一页", callback_data="next_page"))
if nav_buttons:
keyboard.append(nav_buttons)
keyboard.append([InlineKeyboardButton("🔄 重新查询", callback_data="query_logs")])
reply_markup = InlineKeyboardMarkup(keyboard)
await query.edit_message_text(
message,
reply_markup=reply_markup,
parse_mode=ParseMode.MARKDOWN
)
@whitelist_required
async def handle_pagination(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""处理分页"""
query = update.callback_query
await query.answer()
search_params = context.user_data.get('search_params')
if not search_params:
await query.edit_message_text("❌ 错误:搜索参数丢失,请重新开始。")
return
if query.data == "prev_page":
search_params['current_page'] = max(0, search_params['current_page'] - 1)
elif query.data == "next_page":
search_params['current_page'] += 1
await perform_search(update, context)
async def error_handler(update: Update, context: ContextTypes.DEFAULT_TYPE):
"""错误处理"""
logger.error(f"异常发生: {context.error}")
if update.effective_message:
await update.effective_message.reply_text(
"❌ 发生了一个错误,请稍后再试。"
)
async def shutdown(application):
"""关闭时清理资源"""
await es_client.close()
def main():
"""主函数"""
# 创建应用
application = Application.builder().token(TELEGRAM_BOT_TOKEN).build()
# 添加处理器
application.add_handler(CommandHandler("start", start))
application.add_handler(CallbackQueryHandler(query_logs, pattern="^query_logs$"))
application.add_handler(CallbackQueryHandler(handle_index_pagination, pattern="^index_(prev_page|next_page)$"))
application.add_handler(CallbackQueryHandler(select_index, pattern="^index_"))
application.add_handler(CallbackQueryHandler(select_time_and_search, pattern="^time_"))
application.add_handler(CallbackQueryHandler(handle_pagination, pattern="^(prev_page|next_page)$"))
# 添加错误处理器
application.add_error_handler(error_handler)
# 启动机器人
print("🤖 Elasticsearch 日志查询机器人启动中...")
application.run_polling(drop_pending_updates=True)
if __name__ == "__main__":
main()
运行测试:
没加白名单时,访问

加了白名单,可以正常访问,索引页分页显示成功