Table of Contents
一、Beautiful Soup简介
爬虫正则表达式参考:Python 爬虫正则表达式和re库
在爬虫过程中,可以利用正则表达式去提取信息,但是有些人觉得比较麻烦。因为花大量时间分析正则表达式。这时候可以用高效的网页解析库Beautiful Soup。
Beautiful Soup 是一个HTML/XML 的解析器,主要用于解析和提取 HTML/XML 数据。
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, “html.parser”) | 1. Python的内置标准库 2. 执行速度适中 3.文档容错能力强 | Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, “lxml”) | 1. 速度快 2.文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, [“lxml”, “xml”]) BeautifulSoup(markup, “xml”) | 1. 速度快 2.唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, “html5lib”) | 1. 最好的容错性 2.以浏览器的方式解析文档 3.生成HTML5格式的文档 | 速度慢,不依赖外部扩展 |
二、Beautiful Soup 安装
Beautiful Soup 3 目前已经停止开发,推荐在现在的项目中使用Beautiful Soup 4,不过它已经被移植到BS4了,也就是说导入时我们需要 import bs4。
安装Beautiful Soup
pip install beautifulsoup4 |
根据操作系统不同,可以选择下列方法来安装lxml,安装解析器:
apt-get install Python-lxmleasy_install lxmlpip install lxml |
创建对象时,指定解析器,这里为lxml
from bs4 import BeautifulSoupbs = BeautifulSoup(html,"lxml") |
三、Beautiful Soup 使用
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种: Tag , NavigableString , BeautifulSoup , Comment .
(1)Tag
标签,最基本的信息组织单元,分别用<>和标明开头和结尾,通俗点讲就是 HTML 中的一个个标签。
Tag有很多方法和属性,tag中最重要的属性: name和attributes。
name:
每个tag都有自己的名字,通过 .name 来获取:
惯例,同样以豆瓣电影排行做分析,链接为:https://movie.douban.com/top250
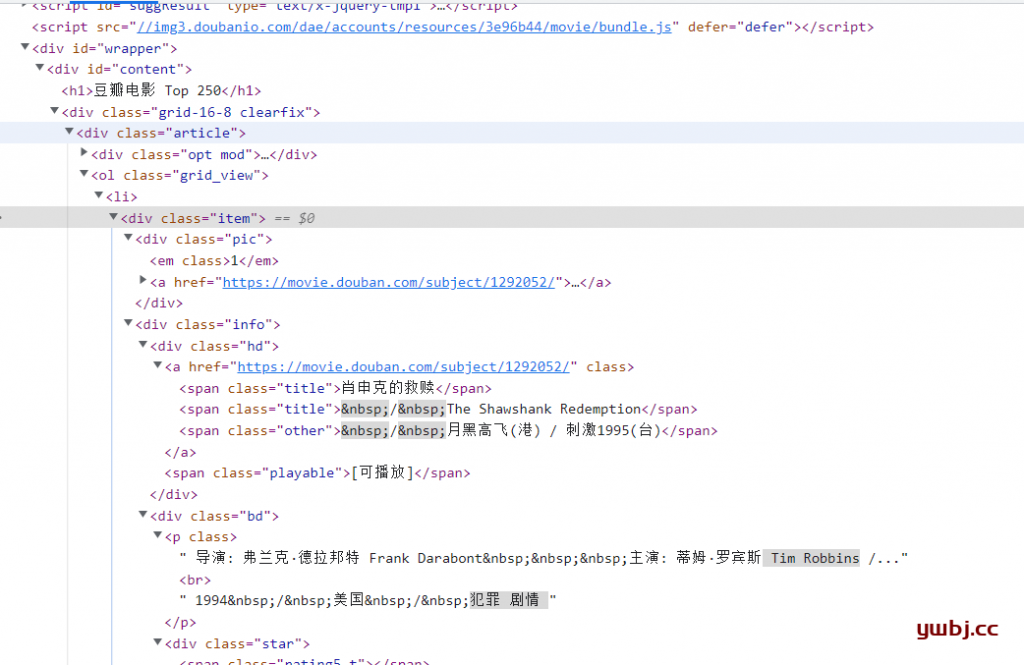
import requestsfrom bs4 import BeautifulSoupheaders = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/65.0.3325.162 Safari/537.36'}url='https://movie.douban.com/top250'req=requests.get(url,headers=headers)html=req.text#print(req.text)soup=BeautifulSoup(html,'lxml')print(soup.h1)print(soup.a) |
执行结果:
<h1>豆瓣电影 Top 250</h1> <a class="nav-login" href="https://accounts.douban.com/passport/login?source=movie" rel="nofollow">登录/注册</a> |
以上,就直接提取到标签h1和a 的内容了,只所以只有一个,因为只提取第一个匹配到的内容。
Attributes:
属性,一个tag可能有很多个属性, . tag的属性的操作方法与字典相同。
如上:ol class=”grid_view” 的属性, 标签名为ol,属性为class,属性值为:grid_view
import requestsfrom bs4 import BeautifulSoupheaders = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/65.0.3325.162 Safari/537.36'}url='https://movie.douban.com/top250'req=requests.get(url,headers=headers)html=req.text#print(req.text)soup=BeautifulSoup(html,'lxml')#获取标签div所有属性,得到的是一个字典print(soup.div.attrs)#获取标签ol属性为class的值print(soup.ol['class']) |
执行结果:
{'id': 'db-global-nav', 'class': ['global-nav']} ['grid_view'] |
因为是字典属性,所以tag的属性可以被添加,删除或修改。不过,对于修改删除的操作,不是我们的主要用途,有需要的自行参考官方文档。
(2)NavigableString
直译为:可以遍历的字符串,通过名称可知,得到字符串。
标签内非属性字符串,格式:soup.\.string, NavigableString可以跨越多个层次。
如,得到了标签的内容,要想获取标签内部的文字,用 .string 即可。
上面代码改为:
print(soup.h1.string) |
执行结果:
豆瓣电影 Top 250 |
(3)BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型,名称。
print(soup.name) |
执行结果:
[document] |
(4)Comment
注释及特殊字符串,Tag , NavigableString , BeautifulSoup 几乎覆盖了html和xml中的所有内容,但是还有一些特殊对象.容易让人担心的内容是文档的注释部分:
from bs4 import BeautifulSoupmarkup = "<b><!--Hey, buddy. Want to buy a used parser?--></b>"soup = BeautifulSoup(markup)comment = soup.b.stringprint(type(comment))print(comment) |
执行结果:
<class 'bs4.element.Comment'> Hey, buddy. Want to buy a used parser? |
四、遍历文档树
HTML基本格式:<>…构成了所属关系,遍历形成了标签的树形结构。
所以有时候不能做到一步就得到想要的元素,需要先选中一个元素在以它为基准再选择它的子节点,父节点,兄弟节点等。
(1)子节点和子孙节点
子节点属性:.contents .children
.content
tag 的 .content 属性可以将tag的子节点以列表的方式输出
import requestsfrom bs4 import BeautifulSoupheaders = {'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_3) AppleWebKit/537.36 (KHTML, like Gecko)Chrome/65.0.3325.162 Safari/537.36'}url='https://movie.douban.com/top250'req=requests.get(url,headers=headers)html=req.text#print(req.text)soup=BeautifulSoup(html,'lxml')print(soup.ol.contents) |
执行结果:
['\n', <li><div class="item"><div class="pic"><em class="">1</em><a href="https://movie.douban.com/subject/1292052/"><img alt="肖申克的救赎" class="" src="https://img9.doubanio.com/view/photo/s_ratio_poster/public/p480747492.jpg" width="100"/></a></div> <div class="info">... |
输出方式为列表,所以可以用列表索引来获取它的某一个元素。
print(soup.ol.contents[1]) |
.children
返回的不是一个 list,不过我们可以通过遍历获取所有子节点。
print(soup.ol.children) |
执行结果:
<list_iterator object at 0x7fbf14fbc4c0> |
打印输出 .children ,可以发现它是一个 list 生成器对象,所以需要遍历一下获取内容。
for child in soup.ol.children: print(child) |
输入内容和.content差不多。
子孙节点.descendants
如果要获得所有的子孙节点的话,可以调用descendants属性,返回结果还是生成器,所以需要遍历一下输出可以看见span节点
print(soup.ol.descendants)#print(soup.ol.children)for child in soup.ol.descendants: print(child) |
descendants会递归查询所有子节点,得到所有的子孙节点。
(2)父节点和祖父节点
获取父节点.parent
print(soup.ol.parent) |
获取所有祖先节点,同理需要遍历获取。
for parent in soup.ol.parents: print(parent) |
(3)兄弟节点
获取兄弟节点:.next_sibling 和 .previous_sibling
next_sibling和previous_sibling分别获取节点的下一个和上一个兄弟元素。
print(soup.li.next_sibling)print(soup.li.previous_sibling) |
如果节点不存在,则返回 None,实际中通常是字符串或空白,因为空白或者换行也可以被视作一个节点,所以得到的结果可能是空白或者换行。
全部兄弟节点:next_siblings和previous_siblings
分别返回后面和前面的兄弟节点,同理,所有节点需要遍历获得。
print(soup.li.next_siblings)print(soup.li.previous_siblings)for sibling in soup.li.next_siblings: print(sibling)for previous in soup.li.previous_siblings: print(previous) |
(4)回退和前进节点
前后节点:.next_element 和 .previous_element
与 .next_sibling .previous_sibling 不同,它并不是针对于兄弟节点,而是在所有节点,不分层次
比如 head 节点为
<head><title>The Dormouse's story</title></head> |
那么它的下一个节点便是 title,它是不分层次关系的。
所有前后节点:.next_elements 和 .previous_elements
同理,返回的是迭代器,需要遍历获得。
五、搜索文档树
eautiful Soup定义了很多搜索方法,主要用的2个方法:find() 和 find_all()
(1)find_all
语法:find_all(name, attrs, recursive, text, **kwargs)
name:
我们可以根据节点名来查询元素。name可以是:字符串、正则表达式、列表、True、方法
print(soup.find_all('a')) |
因为是Tag类型,我们可以进行嵌套查询.
for a in soup.find_all('a'): print(a.find_all('span')) print(a.string) |
attrs
除了根据节点名查询的话,同样的也可以通过属性来查询。
print(soup.find_all(attrs={'id': 'link1'}))print(soup.find_all(attrs={'name': 'Dormouse'})) |
常用的属性比如class,我们可以直接传入class这个参数。在这里需要注意的是class是Python的保留字,所以在class的后面加上下划线。
print(soup.find_all(class_="title")) |
执行结果:
<span class="title">肖申克的救赎</span>, <span class="title"> / The Shawshank Redemption</span>, <span class="title">霸王别姬</span>, <span class="title">阿甘正传</span> |
(2)find
除了find_all( )方法,还有find( )方法,前者返回的是多个元素,以列表形式返回,后缀是返回一个元素。即第一个元素。
find( )与find_all( )的使用方法相同。
find_parents() 和find_parent():前者返回所有祖先节点,后者返回直接父节点。
find_next_siblings()和find_next_sibling():前者返回后面的所有兄弟节点,后者返回后面第一个兄弟节点。
find_previous_siblings和find_previous_sibling():前者返回前面的所有兄弟节点,后者返回前面第一个兄弟节点。
六、CSS选择器
Beautiful Soup还提供了另一种选择器,即CSS选择器。
soup.select(),返回类型是 list。
同样可以用 标签名、类名、 id 名、组合、属性查找。
(1)soup.select()
获取title标签节点print(soup.select('title'))获取class为title的节点print(soup.select('.title'))获取li标签下的a节点print(soup.select('li a'))查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到print soup.select('a[href="http://example.com/elsie"]') |
(2)嵌套选择
同样可以使用嵌套查询
for ul in soup.select('ul'): print(ul.select('li')) |
(3)获取属性
for ul in soup.select('ul'): print(ul['id']) print(ul.attrs['id']) |
(4)获取文本
for li in soup.select('li'): print('String:', li.string) print('get text:', li.get_text()) |
七、获取豆瓣电影排行首页影片信息
通过以上的方法,现在获取豆瓣电影排行首页的排名、电影名、导演演员、年份类型。
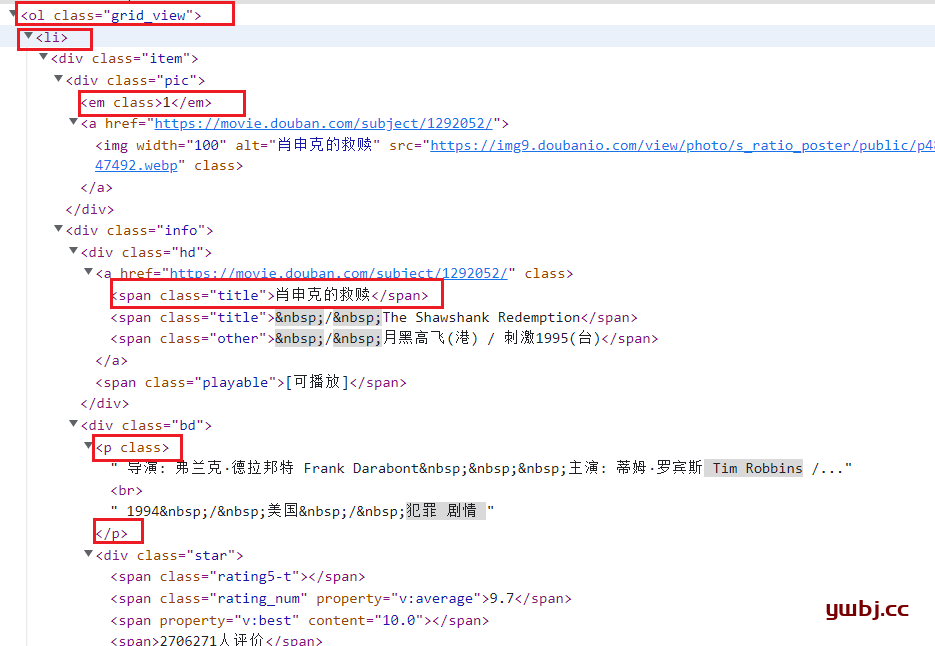
从页面分析,所有影片信息,在class标签值为grid_view的里面。
所以第一步获取所有grid_view里面所有li标签的值,返回的是一个列表。
list= soup.find(class_='grid_view').find_all('li') |
排序,在列表每个元素中,获取em标签值,为排序,只取字符串。
find('em').string |
电影名称,获取第一个title值
find(class_='title').string |
导演和年代信息,在标签p当中,获取的是text文本格式。由于中间有空格,还有br换行符,所以最后还需要replace替换掉。
item.find('p').text.replace(' ','') |
最终代码为:
url='https://movie.douban.com/top250'req=requests.get(url,headers=headers)html=req.text#print(req.text)soup=BeautifulSoup(html,'lxml')list= soup.find(class_='grid_view').find_all('li')for item in list: item_num=item.find('em').string item_name=item.find(class_='title').string item_act=item.find('p').text.replace(' ','') print("排名:"+item_num,"\n电影名称:"+item_name,item_act) |
执行结果:
排名:1 电影名称:肖申克的救赎 导演:弗兰克·德拉邦特FrankDarabont 主演:蒂姆·罗宾斯TimRobbins/...1994 / 美国 / 犯罪剧情排名:2 电影名称:霸王别姬 导演:陈凯歌KaigeChen 主演:张国荣LeslieCheung/张丰毅FengyiZha...1993 / 中国大陆中国香港 / 剧情爱情同性排名:3 电影名称:阿甘正传 导演:罗伯特·泽米吉斯RobertZemeckis 主演:汤姆·汉克斯TomHanks/...1994 / 美国 / 剧情爱情排名:4 电影名称:泰坦尼克号 导演:詹姆斯·卡梅隆JamesCameron 主演:莱昂纳多·迪卡普里奥Leonardo...1997 / 美国墨西哥澳大利亚加拿大 / 剧情爱情灾难排名:5 电影名称:这个杀手不太冷 导演:吕克·贝松LucBesson 主演:让·雷诺JeanReno/娜塔莉·波特曼...1994 / 法国美国 / 剧情动作犯罪排名:6 电影名称:美丽人生 导演:罗伯托·贝尼尼RobertoBenigni 主演:罗伯托·贝尼尼RobertoBeni...1997 / 意大利 / 剧情喜剧爱情战争排名:7 电影名称:千与千寻 导演:宫崎骏HayaoMiyazaki 主演:柊瑠美RumiHîragi/入野自由Miy...2001 / 日本 / 剧情动画奇幻排名:8 电影名称:辛德勒的名单 导演:史蒂文·斯皮尔伯格StevenSpielberg 主演:连姆·尼森LiamNeeson...1993 / 美国 / 剧情历史战争排名:9 电影名称:盗梦空间 导演:克里斯托弗·诺兰ChristopherNolan 主演:莱昂纳多·迪卡普里奥Le...2010 / 美国英国 / 剧情科幻悬疑冒险排名:10 电影名称:星际穿越 导演:克里斯托弗·诺兰ChristopherNolan 主演:马修·麦康纳MatthewMc...2014 / 美国英国加拿大 / 剧情科幻冒险排名:11 电影名称:忠犬八公的故事 导演:莱塞·霍尔斯道姆LasseHallström 主演:理查·基尔RichardGer...2009 / 美国英国 / 剧情排名:12 电影名称:楚门的世界 导演:彼得·威尔PeterWeir 主演:金·凯瑞JimCarrey/劳拉·琳妮Lau...1998 / 美国 / 剧情科幻排名:13 电影名称:海上钢琴师 导演:朱塞佩·托纳多雷GiuseppeTornatore 主演:蒂姆·罗斯TimRoth/...1998 / 意大利 / 剧情音乐排名:14 电影名称:三傻大闹宝莱坞 导演:拉库马·希拉尼RajkumarHirani 主演:阿米尔·汗AamirKhan/卡...2009 / 印度 / 剧情喜剧爱情歌舞排名:15 电影名称:机器人总动员 导演:安德鲁·斯坦顿AndrewStanton 主演:本·贝尔特BenBurtt/艾丽...2008 / 美国 / 科幻动画冒险排名:16 电影名称:放牛班的春天 导演:克里斯托夫·巴拉蒂ChristopheBarratier 主演:让-巴蒂斯特·莫尼...2004 / 法国瑞士德国 / 剧情喜剧音乐排名:17 电影名称:无间道 导演:刘伟强/麦兆辉 主演:刘德华/梁朝伟/黄秋生2002 / 中国香港 / 剧情犯罪惊悚排名:18 电影名称:疯狂动物城 导演:拜伦·霍华德ByronHoward/瑞奇·摩尔RichMoore 主演:金妮弗·...2016 / 美国 / 喜剧动画冒险排名:19 电影名称:大话西游之大圣娶亲 导演:刘镇伟JeffreyLau 主演:周星驰StephenChow/吴孟达ManTatNg...1995 / 中国香港中国大陆 / 喜剧爱情奇幻古装排名:20 电影名称:熔炉 导演:黄东赫Dong-hyukHwang 主演:孔侑YooGong/郑有美Yu-miJung/...2011 / 韩国 / 剧情排名:21 电影名称:控方证人 导演:比利·怀尔德BillyWilder 主演:泰隆·鲍华TyronePower/玛琳·...1957 / 美国 / 剧情犯罪悬疑排名:22 电影名称:教父 导演:弗朗西斯·福特·科波拉FrancisFordCoppola 主演:马龙·白兰度M...1972 / 美国 / 剧情犯罪排名:23 电影名称:当幸福来敲门 导演:加布里尔·穆奇诺GabrieleMuccino 主演:威尔·史密斯WillSmith...2006 / 美国 / 剧情传记家庭排名:24 电影名称:触不可及 导演:奥利维·那卡什OlivierNakache/艾力克·托兰达EricToledano 主...2011 / 法国 / 剧情喜剧排名:25 电影名称:怦然心动 导演:罗伯·莱纳RobReiner 主演:玛德琳·卡罗尔MadelineCarroll/卡...2010 / 美国 / 剧情喜剧爱情 |
八、小结
推荐使用lxml解析库,必要时选择html.parser。相对于正则表达式,Beautiful Soup更加简单,但是网上有些推荐正则表达式,理由是精确。
具体用哪个,还是根据环境选择吧,一起使用都可以。
打赏作者

{kind=link}
Pingback引用通告: python爬虫练习,爬取豆瓣最受欢迎的250部电影,并保存至excel - 运维笔记(ywbj.cc)
Pingback引用通告: python爬虫之selenium库,浏览器访问搜索页面并提取信息,及隐藏浏览器运行 - 运维笔记(ywbj.cc)