Table of Contents
一、单线程常规下载
常规单线程执行脚本爬取壁纸图片,只爬取一页的图片。
import datetime
import re
import requests
from bs4 import BeautifulSoup
start = datetime.datetime.now()
j = 0
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'}
def pic_re(url):
re = requests.get(url=url,headers=headers)
return re.text
def pic_download(soup):
list = soup.find(class_='contlistw mtw').find_all('li')
for item in list:
global j
pic_name = item.find('img')['alt']
pic_url = item.find('img')['lazysrc'].replace('.278.154.jpg','')
pic_type = re.sub(r'h.*\d+.','', pic_url)
#print(pic_name,pic_type,pic_url)
filename = '{}.{}'.format(pic_name, pic_type)
print('开始下载:'+filename)
with open(filename, 'wb') as f:
f.write(requests.get(pic_url,headers=headers).content)
print(filename+' 下载完成')
j += 1
def main():
for i in range(1,2):
url = 'https://desk.3gbizhi.com/deskMV/index_{}.html'.format(i)
html=pic_re(url)
soup=BeautifulSoup(html,'lxml')
pic_download(soup)
date_all = (datetime.datetime.now() - start).total_seconds()
print(f'总共{j}张图片,下载总用时:{date_all}s')
if __name__ == '__main__':
main()
执行结果:
开始下载:站在油菜花地的小清新美女背影.jpg
站在油菜花地的小清新美女背影.jpg 下载完成
开始下载:穿大花袖子连衣裙的印度美女近照摄影.jpg
穿大花袖子连衣裙的印度美女近照摄影.jpg 下载完成
总共24张图片,下载总用时:485.885113s
进程已结束,退出代码0
结果,第一页24张图片,就下载差不多8分钟,排除网络等因素,还没有手动下载快。
二、多线程下载
上面的有两个循环,第一个是页面的循环,一页一页的加载,每页在单独循坏单独下载图片。
所以有两个等待时间,第一个就是等待第一页下载完成,才会到第二页。第二个等待就是每页图片一张下载完才下载第二张。
综上,优化两点:
第一点,第一步提取所有图片链接保存,不用一页等一页的提取。
第二点,所有图片多线程同时下载,不用等一个一个下载。
1:创建列表,储存图片信息
只需要两个信息,图片名称,和图片链接,储存到 pic_list = [] 列表。
pic_list = []
def get_pic_list(soup):
list = soup.find(class_='contlistw mtw').find_all('li')
for item in list:
global j
pic_name = item.find('img')['alt']
pic_url = item.find('img')['lazysrc'].replace('.278.154.jpg','')
pic_type = re.sub(r'h.*\d+.','', pic_url)
filename = 'pic\{}.{}'.format(pic_name, pic_type)
pic_list.append([filename,pic_url])
2:读取列表,多线程同时下载
threading说明:
- 创建空列表t_list,将三个子线程放入该列表,用于执行join,
- 执行子线程(start),start方法开启一个新线程。把需要并行处理的代码放在run()方法中,start()方法启动线程将自动调用 run()方法。
- 执行阻塞 (join),join函数可以理解为,如果某个子进程执行了join函数,那么在该子进程执行到join之前,父进程都会等待。
threading.Thread命令参数:
第一个为参数为函数,第二次参数为函数值。
- 使用args 传递参数 threading.Thread(target=target, args=(10, 100, 100)),args参数为元组,所以只有一个参数,以 , 结尾,例:args=(10,)
- 使用kwargs传递参数 threading.Thread(target=target, kwargs={“a”: 10, “b”:100, “c”: 100})
- 同时使用 args 和 kwargs 传递参数 threading.Thread(target=target, args=(10, ), kwargs={“b”: 100,“c”: 100})
分别创建下载函数,和多线程函数。
代码如下:
def image_down(filename,image_url):
re = requests.get(image_url,headers=headers)
print('开始下载:' + filename)
with open(filename, 'wb') as f:
f.write(re.content)
print(filename + ' 下载完成')
def thread_down():
t_list = []
for url in pic_list:
global j
t = threading.Thread(target=image_down,
kwargs={'filename': url[0], 'image_url': url[1]})
t_list.append(t)
t.start()
j += 1
for t in t_list:
t.join()
最终代码为:
import datetime
import re
import requests
from bs4 import BeautifulSoup
import threading
start = datetime.datetime.now()
j = 0
pic_list = []
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'}
def pic_re(url):
re = requests.get(url=url,headers=headers)
return re.text
def get_pic_list(soup):
list = soup.find(class_='contlistw mtw').find_all('li')
for item in list:
global j
pic_name = item.find('img')['alt']
pic_url = item.find('img')['lazysrc'].replace('.278.154.jpg','')
pic_type = re.sub(r'h.*\d+.','', pic_url)
filename = 'pic\{}.{}'.format(pic_name, pic_type)
pic_list.append([filename,pic_url])
def image_down(filename,image_url):
re = requests.get(image_url,headers=headers)
print('开始下载:' + filename)
with open(filename, 'wb') as f:
f.write(re.content)
print(filename + ' 下载完成')
def thread_down():
t_list = []
for url in pic_list:
global j
t = threading.Thread(target=image_down,
kwargs={'filename': url[0], 'image_url': url[1]})
t_list.append(t)
t.start()
j += 1
for t in t_list:
t.join()
def main():
for i in range(1,24):
url = 'https://desk.3gbizhi.com/deskMV/index_{}.html'.format(i)
html=pic_re(url)
soup=BeautifulSoup(html,'lxml')
get_pic_list(soup)
thread_down()
date_all = (datetime.datetime.now() - start).total_seconds()
print(f'总共{j}张图片,下载总用时:{date_all}s')
if __name__ == '__main__':
main()
执行结果,533张图片,只用了差不多3分钟就下载完了
开始下载:pic\超清4K长发少女,高清到毛孔都看的见强烈推荐.png
pic\超清4K长发少女,高清到毛孔都看的见强烈推荐.png 下载完成
开始下载:pic\超高清长发清纯学生妹街拍电脑背景.jpg
pic\超高清长发清纯学生妹街拍电脑背景.jpg 下载完成
开始下载:pic\图书馆的气质少女高清头像壁纸图片-真8K壁纸推荐.png
pic\图书馆的气质少女高清头像壁纸图片-真8K壁纸推荐.png 下载完成
总共533张图片,下载总用时:182.8669s
进程已结束,退出代码0
三、图片不完整解决
以上虽然速度上来了,但是查看图片有下载失败,如0kb,或者图片不完整,半截是灰色的。
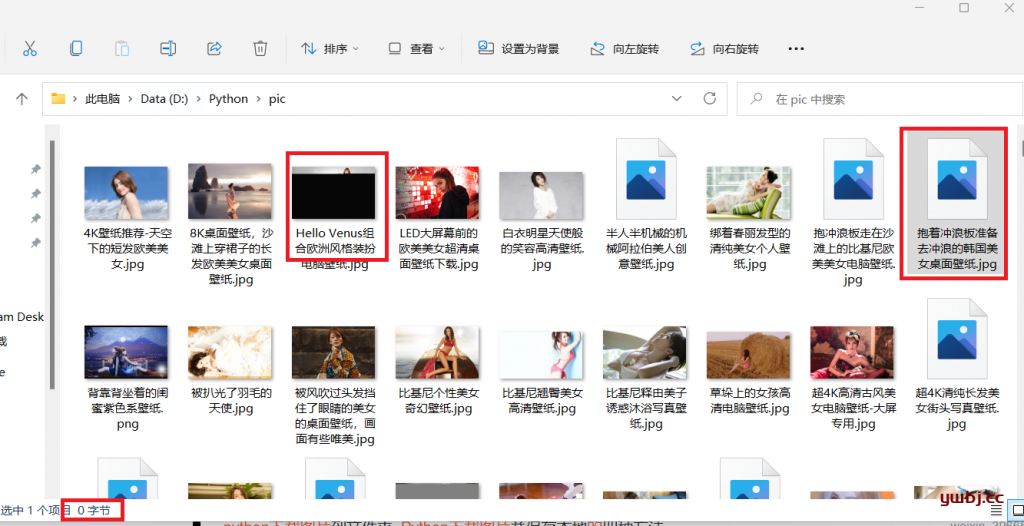
原因多半是网络原因,壁纸多半都是大尺寸,容量也大,图片1M到20M不等,经常会加载不全就下载下来或网络访问失败。
对于网络失败的(0kb),让他返回重新访问。用re.status_code == 200判断即可。
对于下载不全的,用其他的方式下载。这里用
image = Image.open(BytesIO(re.content)
因为这种方法,如果图片下载不全,会报错异常OSError: image file is truncated (X bytes not processed),通过捕获异常,同样重新返回执行。
为了防止因为网络原因,陷入死循环,设置返回次数,超过规定次数,则停止返回。
改image_down函数即可。
from PIL import Image
from io import BytesIO
def image_down(filename,image_url):
re = requests.get(image_url,headers=headers)
if re.status_code == 200:
try:
print('开始下载:' + filename)
image = Image.open(BytesIO(re.content))
image.save(filename)
print(filename + ' 下载完成')
except OSError:
count = 1
print('图片不完整,重新下载')
if count <= 5:
return image_down(filename, image_url)
else:
print(filename + ' 下载失败')
count += 1
else:
count = 1
print('网络错误,重新下载')
if count <= 5:
return image_down(filename,image_url)
else:
print(filename+' 下载失败')
count += 1
再次执行,图片全部下载完成,而且没有不全的图片了。
四、多进程下载
除了多线程之外,我们还可以使用多进程来提高爬虫速度
在Python中multiprocessing提供了两个用于多进程的类,即Process和Pool类
- multiprocessing.Process 无法批量开启子进程,可以直接用multiprocesssing.Queue等进行通信
- multiprocessing.Pool 可以批量开启子进程,不能直接用multiprocessing.Queue进行通信,只能通过共享内存,或者用multiprocessing.Manager()进行进程间通信。
Pool仅在内存中分配正在执行的进程,而Process在内存中分配所有任务,因此,当任务数较小时,我们可以使用Process类;当任务数较大时,我们可以使用Pool。
1、Process(用于创建进程)
multiprocessing模块提供了一个Process类来代表一个进程对象。
在multiprocessing中,每一个进程都用一个Process类来表示。
构造方法:Process([group [, target [, name [, args [, kwargs]]]]])
- start():启动进程,并调用该子进程中的p.run()
- run():进程启动时运行的方法,正是它去调用target指定的函数,我们自定义类的类中一定要实现该方法
- terminate():强制终止进程p,不会进行任何清理操作,如果p创建了子进程,该子进程就成了僵尸进程,使用该方法需要特别小心这种情况。如果p还保存了一个锁那么也将不会被释放,进而导致死锁
- is_alive():返回进程是否在运行。如果p仍然运行,返回True
- join([timeout]):进程同步,主进程等待子进程完成后再执行后面的代码。线程等待p终止(强调:是主线程处于等的状态,而p是处于运行的状态)。timeout是可选的超时时间(超过这个时间,父线程不再等待子线程,继续往下执行),需要强调的是,p.join只能join住start开启的进程,而不能join住run开启的进程
使用方法和多线程threading.Thread的使用方法差不多。
p = Process(target=run_proc, args=('test',))
p.start()
p.join()
如,前面的代码,增加def multiprocess_down()类,同样,同时创建多个子进程,加入列表,子进程并发跑。
from multiprocessing import Process
def multiprocess_down():
p_list = []
for url in pic_list:
global j
p = Process(target=image_down,
kwargs={'filename': url[0], 'image_url': url[1]})
p_list.append(p)
p.start()
j += 1
for p in p_list:
p.join()
...
...
def main():
for i in range(1,3):
url = 'https://desk.3gbizhi.com/deskMV/index_{}.html'.format(i)
html=pic_re(url)
soup=BeautifulSoup(html,'lxml')
get_pic_list(soup)
#thread_down()
multiprocess_down()
date_all = (datetime.datetime.now() - start).total_seconds()
print(f'总共{j}张图片,下载总用时:{date_all}s')
执行结果
开始下载:pic\LED大屏幕前的欧美美女超清桌面壁纸下载.jpg
pic\LED大屏幕前的欧美美女超清桌面壁纸下载.jpg 下载完成
开始下载:pic\手捧窗帘的欧美时尚模特高清壁纸.jpg
pic\手捧窗帘的欧美时尚模特高清壁纸.jpg 下载完成
开始下载:pic\站在油菜花地的小清新美女背影.jpg
pic\站在油菜花地的小清新美女背影.jpg 下载完成
总共48张图片,下载总用时:172.714426s
进程已结束,退出代码0
可以看出,这种多进程,显然没有多线程速度块,虽然也用了多个子进程同时跑,速度提升还是没有多线程速度快。
2、Pool(用于创建管理进程池)
构造方法:Pool([processes[, initializer[, initargs[, maxtasksperchild[, context]]]]])
- processes :要创建的进程数,如果省略,将默认使用cpu_count()返回的数量。
- initializer:每个工作进程启动时要执行的可调用对象,默认为None。如果initializer是None,那么每一个工作进程在开始的时候会调用initializer(*initargs)。
- initargs:是要传给initializer的参数组。
- maxtasksperchild:工作进程退出之前可以完成的任务数,完成后用一个新的工作进程来替代原进程,来让闲置的资源被释放。maxtasksperchild默认是None,意味着只要Pool存在工作进程就会一直存活。
- context: 用在制定工作进程启动时的上下文,一般使用Pool() 或者一个context对象的Pool()方法来创建一个池,两种方法都适当的设置了context。
方法:
- apply(),
函数原型:apply(func[, args=()[, kwds={}]])
该函数用于传递不定参数,同python中的apply函数一致,主进程会被阻塞直到函数执行结束(不建议使用,并且3.x以后不再出现) - apply_async
函数原型:apply_async(func[, args=()[, kwds={}[, callback=None]]])
与apply用法一致,但它是非阻塞的且支持结果返回后进行回调 - map()
函数原型:map(func, iterable[, chunksize=None])
Pool类中的map方法,与内置的map函数用法行为基本一致,它会使进程阻塞直到结果返回
注意:虽然第二个参数是一个迭代器,但在实际使用中,必须在整个队列都就绪后,程序才会运行子进程 - map_async()
函数原型:map_async(func, iterable[, chunksize[, callback]])
与map用法一致,但是它是非阻塞的 - close()
关闭进程池(pool),使其不再接受新的任务 - terminal()
结束工作进程,不再处理未处理的任务 - join()
主进程阻塞等待子进程的退出, join方法要在close或terminate之后使用
Pool.apply_async:异步执行,结果的顺序不能保证与调用的顺序相同
Pool.map:同步执行,阻塞直到返回完整的结果,
map和map_async一次调用一个作业列表,但是apply和apply_async只能调用一个作业。但是,apply_async是在后台并行执行作业的。
我这里用apply_async,也可以用map,但是map正常情况只能传一个参数,要用map传多个参数,用starmap即可。
from multiprocessing import Pool
def multipoll_down():
p = Pool(multiprocessing.cpu_count())
for url in pic_list:
global j
p.apply_async(image_down,[url[0],url[1]])
#p.starmap(image_down, [(url[0], url[1]),])
j += 1
p.close()
p.join()
def main():
for i in range(1, 3):
url = 'https://desk.3gbizhi.com/deskMV/index_{}.html'.format(i)
html = pic_re(url)
soup = BeautifulSoup(html, 'lxml')
get_pic_list(soup)
# thread_down()
# multiprocess_down()
multipoll_down()
date_all = (datetime.datetime.now() - start).total_seconds()
print(f'总共{j}张图片,下载总用时:{date_all}s')
执行结果,速度和process子进程并行差不多(我电脑cpu最大8个进程而已)。
五、协程下载
1:aiohttp 和 asyncio库
这里需要用到两个库aiohttp 和 asyncio。
aiohttp :可以把这个库当作 requests库 的替代品,因为requets不支持异步默认,所以这里需要用aiohttp 库替代requests库。
asyncio:asyncio 是用来编写 并发 代码的库,使用 async/await 语法。
正常的函数在执行时是不会中断的,所以你要写一个能够中断的函数,就需要添加async关键。
async 用来声明一个函数为异步函数,异步函数的特点是能在函数执行过程中挂起,去执行其他异步函数,等到挂起条件(假设挂起条件是sleep(5))消失后,也就是5秒到了再回来执行。
asyncio基本流程
声明协程函数,函数前加async:
async def function():
创建任务:
asyncio.create_task(coro, *, name=None)
两种执行任务,简单等待asyncio.wait和并发执行asyncio.gather
coroutine asyncio.wait(aws, *, timeout=None, return_when=ALL_COMPLETED)
awaitable asyncio.gather(*aws, return_exceptions=False)
运行 asyncio 程序:
asyncio.run(coro, *, debug=False)
Python 3.7 及以后,不需要显式声明事件循环,可以使用 asyncio.run(main())来代替最后的启动操作
asyncio.get_event_loop().run_until_complete(main())
import aiohttp
import asyncio
async def images_down(filename, image_url):
async with aiohttp.ClientSession() as session:
async with session.get(image_url,headers=headers) as resp:
#print(filename,resp.status)
if resp.status == 200:
print('开始下载:' + filename)
with open(filename, 'wb') as f:
# 这个地方通过对流的处理,而不是一下子整体读取。
# 一下子整个的读取,会导致批量下载图片的时候,一开始会出现资源浪费,只下载几张图片
while True:
chunk = await resp.content.read(1024)
if not chunk:
break
f.write(chunk)
print('下载完成:' + filename)
else:
print('网络错误,重新下载:'+ filename)
return await images_down(filename,image_url)
async def aiohttp_down():
for url in pic_list:
global j
task = [asyncio.create_task(images_down(url[0],url[1]))]
j += 1
#await asyncio.wait(task)
await asyncio.gather(*task)
def main():
for i in range(1, 3):
url = 'https://desk.3gbizhi.com/deskMV/index_{}.html'.format(i)
html = pic_re(url)
soup = BeautifulSoup(html, 'lxml')
get_pic_list(soup)
loop = asyncio.get_event_loop()
loop.run_until_complete(aiohttp_down())
#asyncio.run(aiohttp_down())
date_all = (datetime.datetime.now() - start).total_seconds()
print(f'总共{j}张图片,下载总用时:{date_all}s')
执行结果:
下载完成:pic\鸽子飞过欧美性感深V装欧美美女高清壁纸.jpg
下载完成:pic\穿黄色衣服在路边黄花的摄影电脑壁纸.jpg
下载完成:pic\棕色色调穿朝鲜传统服饰的韩国高颜值美女.jpg
下载完成:pic\欧美古城街道摄影的欧美美女.jpg
下载完成:pic\沙滩上捧着花散步的长发美女电脑壁纸.jpg
总共48张图片,下载总用时:18.869591s
进程已结束,退出代码0
48张,只用了18秒左右,协程速度最快。
2:遇到的问题
问题一: RuntimeError: Event loop is closed。
asyncio.run()执行报错,所以改成 asyncio.get_event_loop().run_until_complete(main()),就不报错了,有趣的是,官方是推荐使用asyncio.run()的方法。
问题二: 图片下载速度快,但是大尺寸图片下载不完整。
跟多线程遇到的问题一致,1M到20M的图片,显示不完全,小的图片则正常。
尝试解决方法1:
跟多线程一致的方法,或者判断Content-Length值返回循环下载
f os.path.getsize(filename) != int(resp.headers["Content-Length"]):
return await images_down(filename, image_url)
结果:直接陷入死循环,发现所有下载图片基本不可能和Content-Length一致,即使下载完整。
尝试解决方法2:
用块的方式,导入aiofiles包,通过设置块(content.iter_chunked)的值尝试循环写入。
async def async_http_download(filename, image_url):
async with aiofiles.open(filename, 'wb') as fd:
async with aiohttp.ClientSession() as session:
async with session.get(image_url) as resp:
async for chunk in resp.content.iter_chunked(1024):
await fd.write(chunk)
结果,虽然不完整的减少,但是大尺寸的图,还是有,解决未果。
用aiohttp虽然代替requests库使用,估计功能还是没有requests库完整及全面,等后续在找解决方法。
六、总结
对于多任务爬虫来说,多线程、多进程、协程这几种方式处理效率的排序为:aiohttp协程 > 多线程 > 多进程。
但是aiohttp协程难度有点复杂,需要了解,而且本人目前没有解决协程下载大尺寸图片不完整的情况,还需要后续继续学习。
打赏作者

{kind=link}
{kind=link}
Pingback引用通告: python爬虫之Scrapy框架,基本介绍使用以及用框架下载图片案例 - 运维笔记(ywbj.cc)